


Introduction
Burr IST Ltd have been working with a wide range of customers since 2001 on all sorts of reporting, integration and analysis projects using SQL-Hub, JetViewer and other products.
Over the years we have come across a lot of the same challenges and looked at many ways of solving them
These articles explore some of the things that are often discussed and the pros and cons of a number of different solutions. These discussion are intended to give an understanding of some different types of scenarios and how they can be addressed.
Standardising Data from Different Sources
Sometimes we have systems that contain similar types of data but in a different structure
For example a business might use two different CRM systems in different offices (maybe due to a merger etc). Both systems contain information about accounts, contacts etc but the field names and table names are different and the database structures vary. But we still might want to be able to see all of this data in the same place.
Defining a Common Schema
Before looking at the technical side of combining the data, the first step is to define a "Common Schema" - this is a database structure that captures the information we want to include in a "central view". This doesn't need to include all the data available in all the sources, just the subset you are interested in - it can always be expanded later on. There is no magic bullet to creating this schema (well certainly not without making a big mess) it's a question of analysing the required outputs, how that data is represented in the source systems and how they can be brought together - and then building your new schema.
Transforming and Merging
Defining the Transformation
Once you have defined a common schema you need some sort of a mechanism to transform the data from the source systems into the correct format for the common schema. First you need to define the data transformation. Usually the transformation consists of:
Field Mappings:
Where to find data for a particular field in the common schema, from a particular source schema. Often though it's not just a question mapping field names to field name but something equivalent to a database join is required and/or different elements of the data from one source object need to be applied in different places in the common schema
Value Mappings:
How to map semantic values from the source systems to standard values in the common schema, for example one system might have product types 'Drinks', 'Fruit and Veg', 'Tinned' while another had a similar concept but with different names like 'Beverages', 'Fresh', 'Preserved', or they might just be arbitrary codes like 'A1', 'B3' , 'B1'. We need to define how to map these to the groupings we have defined for the common schema.
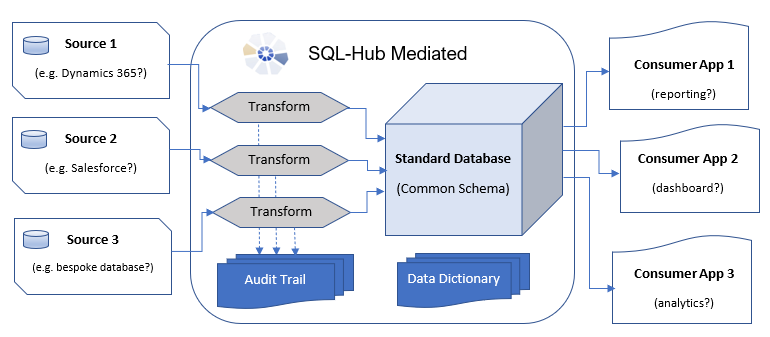
Implementing the Transformation and Load
There are many ways to implement the transformation and loading of the data, none of which are any use unless your common schema and transformation design are workable. Broadly, approaches to transform and load can be grouped in to two types:
On the Fly
The data is transformed at the same time as being transported from the source system. Typically this means the the transformation logic works on a single record at a time - this works great when the objects in the source have a one to one mapping to those in the common schema and you just need to perform straight forward field mappings and value mappings, but can get complicated when you need to reference other data (in the source or the target) to perform the transformation. But it means the whole process could be run on an incremental and possible "near real time" basis.
Transport then Transform
Another approach is to transfer the data for the source system in bulk (this could still be an incremental rather than a batch process) so that you can access all of the data in the source at any point during the transformation. This means you are most likely transporting more data than you actually need and probably running the transformation as a scheduled batch process but that you have all the data easily available to perform complex transformations without the logic getting increasingly more complicated.
This is the approach taken by SQL-Hub mediated